Quick Start Guide
First task submission example
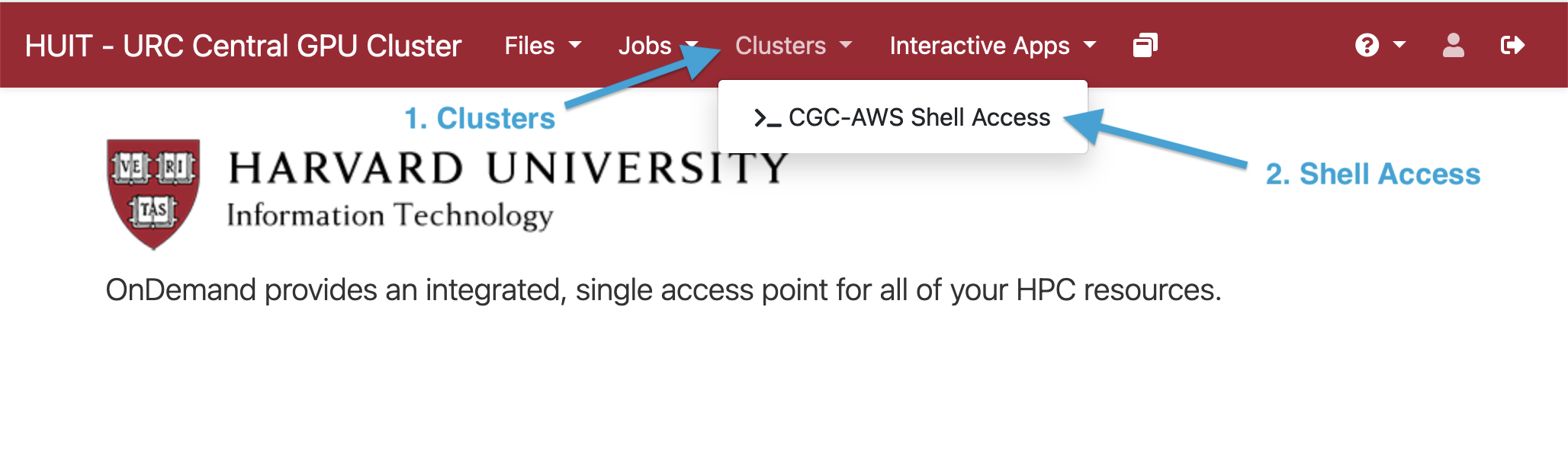
- Go to the OpenOnDemand portal
- Authenticate with Harvard Key.
- Click on the "Clusters" drop-down and then click on "CGC-AWS Shell
Access"
- This should open a command shell. This is running on a login node on
AWS.
- From the shell, we can run either an interactive job or a batch job, described. These will allocate a compute node to run a job in. You should not run computations directly in the login node shell.
Interactive Job
Interactive jobs let you run commands directly in the shell. They are useful for testing and exploration.
To get an interactive job, try the following command:
salloc --nodes=1 --ntasks=1 --cpus-per-task=8 --time=1:00:00 --partition=a100-xl --gres=gpu:1 --mem=16GB --job-name=interactive-test
Option explanation:
--nodes: number of nodes to allocate--ntasks: number of tasks to run per node--cpus-per-task: number of CPU cores to allocate per task. In this case we have one task, so it is the total number of CPU cores we are requesting.--time: how long to allocate the job runtime for. If this time runs out, your job will be killed. Specified here as: HH:MM:SS--job-name: name for the job, will make it easier to locate in jobs list--mem: CPU memory (RAM) to allocate for this job. If specified without a unit (GB), then it is in megabytes--gres: specify the number of additional resources, especially GPU's.--gres=gpu:1means we are requesting one GPU for our job.
If successful, the shell should say:
salloc: Granted job allocation 130
salloc: Waiting for resource configuration
NOTE: your job ID number will show up instead of 130
You can check the status of the job in another terminal:
squeue -l
You should see a list of jobs. Look at the row with your jobid, and check the
column for "STATE". It will likely say "CF" or "CONFIGURING". Unlike Slurm on a
phyical cluster you may be used to (e.g. FASRC Cannon Cluster), when you
request at job it needs to allocate the job from the cloud provider, so the
initial state will be CONFIGURING instead of PENDING (ie. in the queue). It
can 5-10 minutes to allocate a job.
Once the job is allocated, the screen should say:
salloc: Nodes [...] are ready for job`, and return you to an input prompt. Anything you run on this shell will run on the compute node.
We can now run a command:
E.g. lscpu to check the number of CPU's allocated to the job.
When we are done with the interactive job, we can run exit to exit the
interactive shell and relenquish resources.
Batch Job (non-interactive)
Batch jobs do not allow the users to easily interact with them while they are running. They are useful for submitting compute jobs where the inputs are known in advance.
To run a batch job, you first define a file and then submit it to the cluster.
Here is an example sbatch file -- you can create it by opening a text editor
(e.g. nano sbatch-test) and pasting the following text.
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --tasks=1
#SBATCH --cores-per-task=8
#SBATCH --time=04:00:00
#SBATCH --partition=a100-xl
#SBATCH --mem=16GB
#SBATCH --job-name=test-sbatch
#SBATCH --output=myjob_%j.out
#SBATCH --error=myjob_%j.err
#SBATCH --gres=gpu:1
# run code here
echo code goes here
Parameters are defiend by bash comments at the top of the file which start with
#SBATCH. Most of the sbatch paramters are the same as the salloc parameters
described above. Output and error are unique to sbatch and described below.
--output=myjob_%j.out: this tells Slurm which file to write standard command line output to (STDOUT). The file will be created if it does not exist. This can be either an absolute or relative path. Relative paths are taken relative to where the user calls the sbatch command from. There are a few special characters such as%jyou can use in the job name.%jwill be replaced by the job ID.--error=myjob_%j.err: the is the file slurm will write error messages to (STDERR)
In this case, if my submitted job is assigned a jobid of 130, slurm will create
two text files in my current directory: myjob_130.out and myjob_130.err.
You can open the text files with less:
less myjob_130.out
You can also watch the log file in real-time as the job runs with tail:
tail -f myjob_130.out
NOTE: if you only provide a output file and not an error file, both output and error will be written to the output file.
To submit the file as a job, we use the sbatch command:
sbatch sbatch-test
This will queue and run the job in the background, without blocking your shell.
We can check the status of the job with squeue