GPU Cluster Overview
Brief description of the Harvard Central GPU Cluster
In FY25, OVPR partnered with University RCD to build a Central GPU cluster to support the ever-growing use of Artificial Intelligence broadly across Harvard’s research enterprise. The Central GPU service strives to (1) empower interdisciplinary AI/ML research, (2) meet the increasing demand for GPUs and (3) mitigate costly individual GPU investments by Labs/Centers. In addition, this service lowers the barrier to entry by providing simple HarvardKey access as well as seamless access to both on-prem and cloud computing resources under the same user interface. This year, a minimum viable product (MVP) for both cloud and on-prem resources will be completed with a new partnership between TPS cloud engineers and Univ RCD systems engineers.
Key benefits and features
- Familiar web front end for HPC with Open OnDemand
- Provides a scale-out high-performance computing environment with AWS ParallelCluster. This provides access to a variety of accelerator technology and direct access to other AI tools can be integrated upon request.
- Access to familiar HPC cluster management interface for job scheduling through Slurm
- High-performance filesystem through Weka, which is tiered to an underlying object store, AWS S3 and NESE Disk in MGHPCC.
- Globus provides a secure, unified interface to your research data. Use Globus to 'fire and forget' high-performance data transfers between systems within and across organizations.
Architecture Overview
The Central GPU service provides a single front end web-interface to submit to multiple back-end resources.
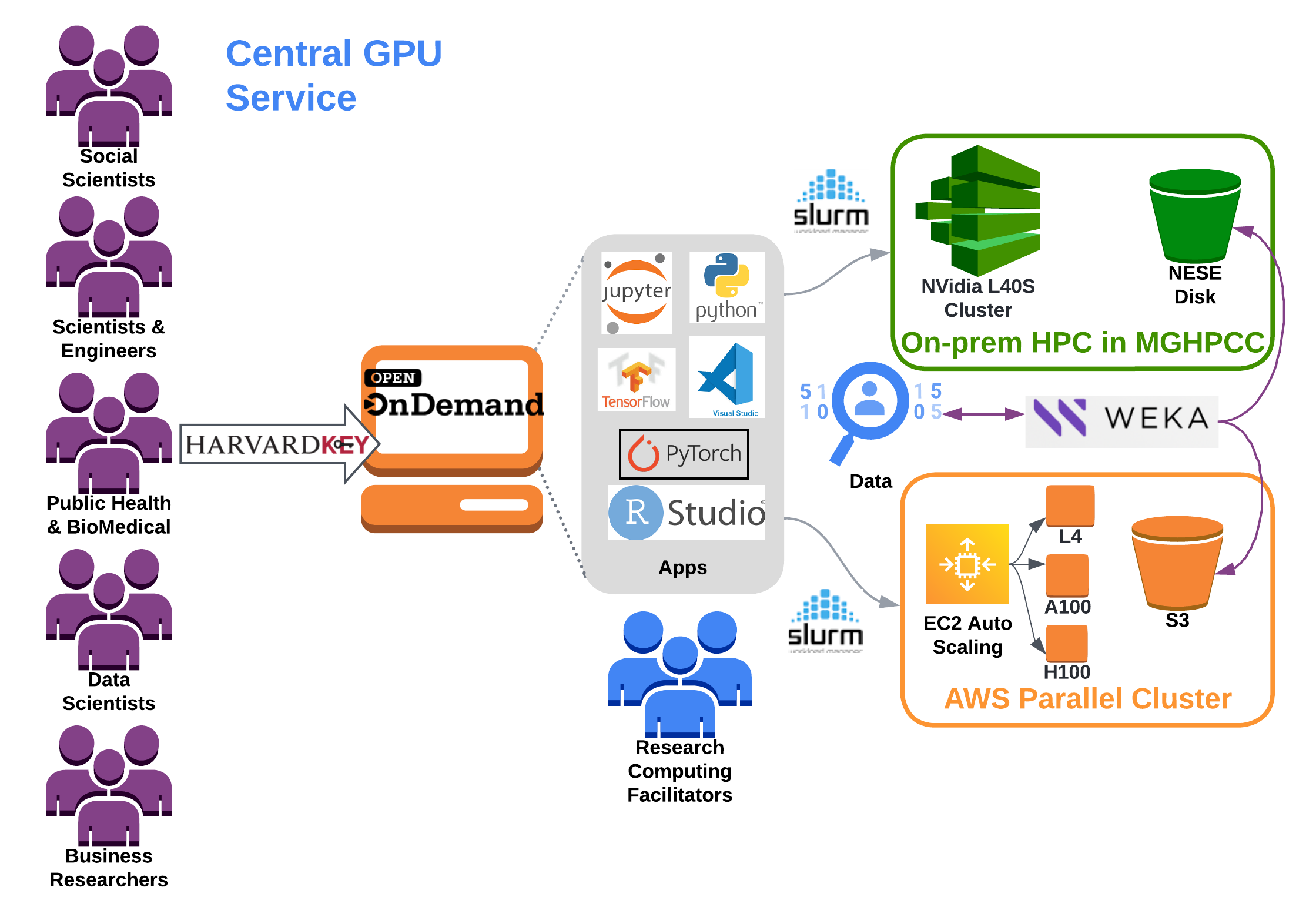
Software and Data will be provided across both platforms.